
Tabula home screen
We encounter the initial challenge of working with the finding aid for Rosenzweig’s partial archive in the aid’s file format, which is a PDF file. At first, I wrote the University of Kassel archive to request a Word copy of the finding aid, which would have allowed us to skip most of what is to come. Unfortunately, they only have the PDF copy of the aid, which was first compiled by Silke E. Wahle in 2007. So, to get the data out of the finding aid, one can use Adobe Acrobat Pro to convert a PDF to a Word (.doc) or Excel (.xls) file format. But my first attempts to use Acrobat produced convoluted results, too messy to work with on a large scale. Instead, we will use a program called Tabula, which is designed to extract data tables from PDF documents.
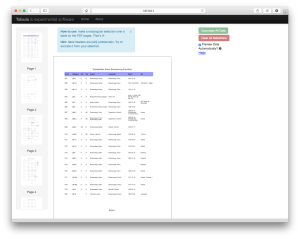
Tabula home screen
After downloading and installing Tabula, the program is easy to use. (Note that you may need a Java update, click here to get Java for OS X.) Tabula will open in your browser, although it does not need internet connectivity. From the home screen (pictured above):
- Select the PDF document from which you want to extract data tables,
- Leave “Auto Detect Tables” unchecked,
- And hit submit.
It will take a second to process the PDF, which for simplicity’s sake I will refer to as the finding aid henceforth. After Tabule finishes processing, a home screen should appear with a preview of the document on the right, and thumbnails of the other pages on the left, as to the right.
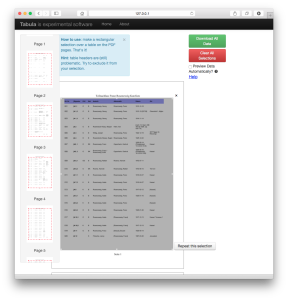
Select data tables
And here enter our first two instances of choices, moments of translation, we face in working with the finding aid. In order to foreground the data collected in the tables, I first choose to exclude the document title, because this can be reentered at a later stage, but include the document headings. To begin the data table extraction:
- Click on the document to select the area you want to extract,
- Hit “Repeat this selection” to apply to all pages,
- Scroll through to make sure all the data is included in your selections,
- And hit “Download All Data” and “Download CSV.”
The result will be a spreadsheet that we can edit with Excel – Click here to download my Tabula extracted data set. As we see below, the data is organized by column A) is its catalog number, B) archival call number, C) sorting by original or a copy, D) category [B = letter, W = manuscript, L = document, S = collection], E) author F) addressee, G) date, H) place (of creation).

Yet if we take a closer look at the some 900 rows of data, it becomes clear that another moment of translation is upon us. Many entries on the first page fit well with the original document, as above. Yet many, as below, do not:
![]()
In order to clean up the data so that it will work with visualization software, we must align document creators, recipients, dates, and places to correspond respective columns. Excel works well for such a task, which involves a lot of cutting and pasting and consulting the original document. As in Rosenzweig’s theory of translation, I want to make clear at this point the curatorial criteria by which I worked through the spreadsheet:
- I tried to retain all data points, especially, manuscripts, letters, and documents, which included author date or place,
- significant was keeping both copies and originals, in order to convey the mixed provenance nature of the material in the archive,
- the original finding aid provided a point of reference where the PDF to CVS extraction produced confusing results, including expanding multiple documents listed on the same line or multiple columns that had been collapsed during extraction,
- I discarded information to specific to be helpful in the visualization, such as location beyond city, whether a letter was dated or postmarked on a certain day, etc.
You can download my refined data here. But even with this cleaned version, there remain letter transpositions, character recognition errors with “ü” and “ä,” and variations in spelling to a degree outstripping the capabilities of Excel alone.